本文记录一些代码审查套路,在看到小伙伴写出某些代码的时候可以告诉他这样写有锅
我在各个项目里面进行代码审查,我维护了很多个项目
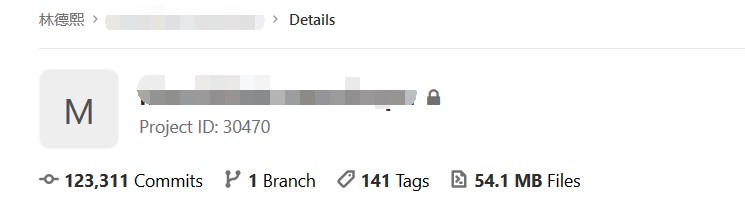
这是我截图某一天的一个核心项目的在 Gitlab 上的 MR 情况,我觉得头像应该是不用保密的,这样知道的小伙伴自然就知道了。对了,那些挂了超过3天的都是标记 WIP 还在开发中的
回到主题,代码审查时有哪些套路?
多语言
如果写了固定的在界面显示的字符串,请询问是否需要使用多语言
魔数的处理
啥是魔数?写固定的一些数值等
魔数尽量不要出现,抽成常量,便于修改,一定避免不了使用魔数的话添加详细注释
如以下代码,后续维护难度几乎等于无穷
Foo(1, 200, 15, 16, 20);
注释
注释说的是不是和代码做的相同
有时候改动的时候忘记改注释了,此时注释说的和代码做的不是一回事,因此代码审查不要跳过注释写的内容哦。看看是否注释里面说的和实际代码做的是否相同
有时候通过读一下注释,然后看一下代码实现,可以发现一些问题,比如开发者正在解决 x-y 问题,比如开发者要么逻辑写反了要么注释写反了
注释内容缺乏意义
比如看到注释里面就写了很浅显做了什么,而没有更多的信息。此时推荐就是带上“为什么”的内容,即注释里面有包含“做什么”和“为什么”会更优
举一个代码审查例子,如代码审查看到以下代码
// 参数校验。
if (stringValue.Length > 6)
{
return false;
}
看到以上的代码,似乎大家都知道这是在做参数的校验。但是为什么要如此校验,为什么使用 6 这个魔数呢?这是注释和代码里面没有告诉咱的内容
以下是我给出的代码审查
我也知道是参数校验…… 但是我不知道的是为什么需要判断 stringValue.Length > 6 的值,这是为什么呢?
大多数的注释都是写这些内容:
- 流程调用逻辑,比如“步骤1做什么步骤2做什么”等等
- 解决什么问题,如 “将从 0 开始的索引转换为从 1 开始的索引,解决界面效果不符合大众日常从 1 开始的习惯”
- 复杂算法解释,如 “这里采用极坐标系进行xxx计算”
- 外部引用链接,如 bug 链接,如博客链接
- 关联模块,例如“根据 Xxx 类的 Xxxx 方法,做 xx 内容”等
变量名拼写 语法规范
变量名拼写是否符合语法,符合规范
这部分其实用机器人来自动审查代码是不错的,如 GitHub 的代码风格自动审查机器人 CodeFactor 可以自动审查代码风格
在没有带序号重载的 Where 中谨慎使用 i 变量
大部分时候使用 Linq 的 Where 和 Select 等函数,默认是有多个重载的,其中一个重载是带上序号的,如下面代码
var n = new List<int>();
n.Where((t, i) =>
{
});
以上的 t 表示的是某个元素,而 i 表示的是此元素的序号。因此在没有使用序号的 Where 中,谨慎使用 i 变量。因为 i 变量按照约定是用在带序号的重载作为表示元素的序号
如以下代码,刚好 List 的元素类型也是 int 类型,写着也许就忘了下面代码的 i 其实表示的是 List 的元素而不是序号
var n = new List<int>();
n.Where(i =>
{
});
该加单位的属性是否明确了单位
用的最多的就是时间单位,请问如下属性表示的是秒还是毫秒
public double Foo { get; }
要么让类型可以表示时间的单位,要么在属性命名上区分,请看 程序猿修养 给属性一个单位
函数的参数个数不要太多
太多的参数调用起来也不方便,代码可读性也比较渣
public void CubeAdsorb(Point start, Point end, Point topLeft, List<Point> points, double theta, Matrix backMatrix, Vector vector, Cube cube)
太多的参数建议定义一个新的类或结构体用来包装
判断逻辑判断方法不要随意倒换
其实只要固定下来,可读性会比较好,如以下反例
internal FontStyle(int style)
{
Debug.Assert(0 <= style && style <= 2);
_style = style;
}
这是 WPF 框架源代码的 FontStyle 类的代码,可读性比较渣的代码是 0 <= style && style <= 2 因为判断方法存在一次倒换。第一次判断是使用常量和变量判断,第二次反过来
当然,适应之后也会发现其实上面的写法也是有一些可读的,因为可以和数学一样表示一个区间
注意外部属性或字段的变更
有很多代码写的时候需要考虑多线程访问,多线程的时候可能其他线程会变更外部的属性或字段,因此如下面代码是不安全的
if (s_providers == null)
return null;
EncodingProvider[] providers = s_providers;
上面代码的 s_providers 的定义是一个静态字段,上面代码在判断 s_providers == null 时,此时 s_providers 是存在值的。但是后续获取 providers = s_providers 时,可能此时的 s_providers 的值就被改为 null 此时的逻辑是不对的
推荐的写法如下
EncodingProvider[] providers = s_providers;
if (providers == null)
return null;
先获取外部字段放在局部变量,再判断局部变量。这样能解决两次访问外部字段的时候,访问的对象不是相同的对象
属性的获取应该是轻量的
从 C# 的设计上,使用属性可以做到对字段或内存空间的封装,可以在获取之前进行一些运算。但是咱默认的约定应该是属性的获取应该是轻量的运算,最好不要做 IO 或重计算,如下面代码
public string Foo
{
get
{
// 访问数据库
// 读写文件
return xx;
}
}
因为大部分小伙伴在使用属性的时候都是不期望去看 get 的代码,都是认为有这个属性可以获取,也许会写入如下面代码
for (int i = 0; i < n; i++)
{
F1(Foo);
}
也就是在循环里面不断获取属性,而这个属性获取的性能又比较差
如果属性的获取的性能比较差,推荐修改为方法,如 GetFoo 这样小伙伴看到方法也有预期
通过局部变量简化获取属性的属性的写法
如看到以下的代码,会觉得代码很复杂
var f1 = Axxx.Bxxxxx.Cxxxxx;
var f2 = F3(f1, Axxx.Bxxxxx.Dxxxxx);
F4(f2, Axxx.Bxxxxx.Exxxxx);
如果此时将 Axxx.Bxxxxx 提取出来,相对来说代码看起来就没有那么多
var bxx = Axxx.Bxxxxx;
var f1 = bxx.Cxxxxx;
var f2 = F3(f1, bxx.Dxxxxx);
F4(f2, bxx.Exxxxx);
小心属性的属性的属性的写法中途存在空值
尽可能不要太多层的属性的属性的写法,如下面代码,听说下面这行代码抛了一个空异常,请问哪个是空
var foo = A.B.C.D.E.F.G;
事件的加等
推荐存在重入的方法对事件加等之前使用减等,至少多余的减等没啥坏处,但是可以解决某些事件被添加多次
public void Foo()
{
F1Event += F2;
}
此时如果存在多次的加等,那么 F1Event 触发一次将会调用两次 F2 方法。而这个逻辑在开始写的时候应该是没锅,但是后续小伙伴改动的时候也许会多调用一次 Foo 方法,此时就炸了
修改后的代码如下
public void Foo()
{
F1Event -= F2;
F1Event += F2;
}
第一次进入的时候,假设 F1Event 是空,此时 F1Event -= F2 没有任何作用,也不会出错。但是如果是第二次进入的时候,就可以做到干掉之前监听的事件
好,第二个问题就是应该让减等跟随加等,放在相邻的两句代码。如果不遵守会如何,如下面的故事。逗 A 说德熙说要先减等然后再加等,好我写了下面的代码
public void Foo()
{
F1Event -= F2;
// 其他的业务
F1Event += F2;
}
然后逗 B 就改了上面的逻辑,中间加了有趣的逻辑,例如再次调用自身
public void Foo()
{
F1Event -= F2;
// 其他的业务
Foo();
F1Event += F2;
}
请问上面代码会有什么坑?第一次调用 F1Event 的减等,此时 F1Event 没有被 F2 监听。而第二次调用 Foo 方法,此时 F1Event 没有被 F2 监听。然后在 Foo 里面调用了 F1Event += F2 加等一次,接着再来一次加等,最后也就是会加等两次
因此推荐上面的规则,让减等和加等放在相邻的代码,如下面代码
public void Foo()
{
F1Event -= F2;
F1Event += F2;
}
此时没有在加等和减等插入逻辑,基本上除非是多线程,那么最终只是监听一次
先执行再加等事件
大多数的业务,都需要先加等事件再执行业务,否则在遇到有多线程的时候,可能就是偶尔是另一个线程先执行完成,而事件还没有加等,因此没有收到通知
// 执行 A 业务
foo.A();
foo.AChanged += Fx;
推荐的是先执行事件的加等,然后再执行逻辑。当然,这个和具体业务是相关的,也许业务上就是想要忽略一次事件
// 先加等事件,这样 A 执行完触发事件就可以被收到
foo.AChanged += Fx;
// 执行 A 业务
foo.A();
如果有看到事件的加等,请看一下是否可以放在业务的最开始
警惕 using 释放时机
在 C# 的 using 释放资源语法里面,可以直接写 using 不带范围,如下面代码
using var fileStream = File.OpenRead(file);
以上代码的 using 释放将会在当前作用域结束时执行释放,如果直接放在方法内的最外层花括号内,可以认为是在方法结束前才释放。于是此时可能导致一些非预期的释放时机问题,比如没有及时释放
using var fileStream = File.OpenRead(file);
// 对 file 文件进行一些处理,可能会因为 FileStream 依然占用 file 文件而失败
对于一些明确时机的逻辑,修改为明确范围会更好
using (var fileStream = File.OpenRead(file))
{
}
File.Delete(file);
如果方法属于一个简单逻辑,那维持代码简单也不错。这一个代码审查点属于需要警惕的内容,而不是一定说哪个写法更好
静态构造函数
避免在静态构造函数中初始化静态字段
先看一个差的例子,以下代码的 Bar 类型在静态构造函数里面里面初始化静态字段。这将会导致无论碰到 Bar 的哪个成员,都会执行静态构造函数初始化静态字段
static class Program
{
public class Bar
{
private readonly static int _value;
public static int Value => _value;
static Bar() => _value = Initialize();
public static void Invoke() { }
}
private static bool _initialized;
static void Main()
{
Bar.Invoke();
Debug.Assert(_initialized == true);
}
private static int Initialize()
{
_initialized = true;
return 123;
}
}
再看一个好的例子,不写静态构造函数,如以下代码。以下代码在调用 Foo 的 Invoke 静态方法,由于 Inovke 静态方法用不着任何静态字段,此时的 _value 字段的赋值是没有被调用的,通过 Program 的 _initialized 字段即可了解到
static class Program
{
public class Foo
{
private readonly static int _value = Initialize();
public static int Value => _value;
public static void Invoke() { }
}
private static bool _initialized;
static void Main()
{
Foo.Invoke();
Debug.Assert(_initialized == false);
}
private static int Initialize()
{
_initialized = true;
return 123;
}
}
不在静态类型里面为了给静态字段赋值而编写静态构造函数,可以提升一点点初始化性能。以上这两个写法是在 IL 层面有微小的差别的,代码审查看到伙伴编写的代码里面如果他的静态构造函数只是为了给静态字段赋值,则可以考虑干掉静态构造函数
详细请参阅 为什么应该尽可能避免在静态构造函数中初始化静态字段? - Artech - 博客园
避免在静态构造函数修改状态
大家都知道,静态构造函数只有类型首次被碰到时,才会执行。于是业务方将难以控制静态构造函数的执行时机,毕竟大家都不能确定自己是否首次碰到静态构造函数所在的类型。更可怕的是实际在编写代码的时候能够明确知道静态构造函数执行的时机,随着后续软件的迭代,可能逐渐就不明确了
一个不能明确执行时机的静态构造函数只应该做一些当前类型的初始化逻辑,比如静态属性或字段的赋值。如果在静态构造函数添加一些状态修改,比如加等某个事件等,这时候将可能因为静态构造函数的执行时机不确定,从而导致状态难以控制。比如说有业务依赖在静态构造函数添加事件获取事件的通知,在某次迭代时修改了类型的首次访问时机导致修改了静态构造函数的加等事件时机,此时将可能遇到事件触发了,但是静态构造函数里面加等的方法没有被调用。这可能正是因为由于静态构造函数的延迟调用,导致静态构造函数没有在事件的触发之前加等事件
一个不能明确执行时机的静态构造函数,如果访问类型之外的其他类型,可能由于过早时机导致被访问的类型存在某些状态没有初始化,也就是可能出现未知的空异常
由于静态构造函数是在首次类型访问时触发,执行线程难以确定,这将会导致可能出现潜在的多线程安全问题。比如对 WPF 等 UI 框架项目来说,非 UI 线程访问 UI 线程上创建的资源可能抛出异常,静态构造函数无法明确调用线程,将可能导致在某些用户端玄幻的抛出后台线程访问 UI 元素的异常,且难以复现
静态构造函数是在首次类型访问时触发,且只触发一次。如果多线程同时进入首次访问,将只让一个线程执行,其他线程进入锁状态。如果静态构造函数逻辑过于复杂,将可能出现潜在的锁问题
为了保证代码的稳定性,我十分推荐只在静态构造函数添加非常简单的逻辑,只对一点点属性和字段赋值。如果必须在静态构造函数添加复杂的逻辑,请尽量确保不会发生如下问题:
- 多线程访问安全问题。尽量不要假设静态构造函数一定在某个线程执行,除非真的非常明确
- 多线程执行的锁的问题。静态构造函数自带一个锁,请关注是否多线程访问过程调用存在锁等待
- 执行时机。加等事件等修改状态行为,必须确保时机乱序时能够符合预期工作。或在一个明确的时机强行触发静态构造函数
框架层对外抛出事件捕获异常
在编写框架层或者基础库的逻辑,需要对外抛出事件,那么推荐捕获对外抛出的事件抛出的异常,不要让事件抛出的异常影响到逻辑
因为对外抛出的事件,是给上层业务使用的,如果上层某个业务抛了异常,也许将会影响框架本身。好的设计大部分是捕获此事件抛出的所有异常,然后稳稳执行完成框架的逻辑之后,再次抛出异常或者封装之后抛出
值得考虑的是,重新抛出的异常可以用 ExceptionDispatchInfo 类的辅助。通过 ExceptionDispatchInfo 可以继续原先异常的抛出堆栈,不会丢失信息
字典性能相关
字典的时候需要关注的是两次获取的问题
字典获取值
如需要判断如果字典存在就获取,有下面两个写法
if (Dictionary.TryGetValue(xx, out var foo))
{
}
第二个写法如下
if(Dictionary.ContainsKey(xx))
{
var foo = Dictionary[xx];
}
这两个方法哪个性能好?其实 TryGetValue 只需要获取一次,性能比较好,测试请看下面博客
C# 字典 Dictionary 的 TryGetValue 与先判断 ContainsKey 然后 Get 的性能对比
字典添加值
想要判断如果字典不存在值的时候才添加,也有两个写法
if(!Dictionary.ContainsKey(xx))
{
Dictionary[xx] = foo;
}
另一个写法是采用 .NET Core 2.0 和 .NET Standard 2.1 添加的 TryAdd 方法添加值
使用 TryAdd 方法的性能会更好,不过这个方法是最近才添加的,也许很多小伙伴不知道
Dictionary.TryAdd(TKey, TValue) Method (System.Collections.Generic)
数组 列表 集合的初始化
如果在此上下文中能够明确知道数组 列表 集合将要分配的大小,那么推荐给定一个指定的大小,如下面代码
var foo = new List<int>(10);
此规则不仅适用于 List 同时也适用于 Dictionary 等集合类
给定明确的大小可以减少后续的集合分配内存,提升性能。可以提升内存性能和 CPU 性能。原因是 大部分集合类 底层分配是两倍两倍分配,重新分配的内存需要将原有的拷贝过去。而因为是两倍两倍分配,所以大部分时候都会比需要的多一些
因此给定明确的分配大小可以减少内存分配和拷贝,提升性能
详细请看 List的扩容机制,你真的明白吗? - 一线码农 - 博客园
尽可能的只读的列表或数组
对于函数的返回值或者属性的获取,如果是返回 List 或 IList 的时候,请想一下,是否可以使用只读列表或只读数组代替。参数传入的时候,也考虑一下是否可以使用只读列表或只读数组传入
尽可能使用只读的列表和数组可以减少在后续开发过程中,遇到数组或列表缓存问题以及元素更改问题,同时可以减少很多 ToList 等的调用
空数组使用 Array.Empty 表示
如果是在返回值或传入参数等,表示默认值需要用到空的数组或空的枚举,可以使用 Array.Empty 使用共享的静态的对象。当然了,这也仅仅只推荐对于常用的类型这样使用,因此一旦某个类型是很少使用的,同时也只有很少的逻辑会用到,而且这部分逻辑调用次数非常少,那么就需要考虑浪费这个对象的占用内存空间是否值的。此时调用 Array.Empty 将会因为创建泛形的静态字段而占用一个对象的空间,不会进行释放
字符串的大量拼接使用 StringBuilder 代替
根据字符串的原理,如果进行不断的拼接,将会带来一点性能损耗。原因是每次拼接都会创建新的字符串对象
for (int i = 0; i < n; i++)
{
str += i.ToString();
}
如上面代码将会创建大量中间的字符串对象,而最终需要的对象仅仅只有一个字符串。一个优化的方法就是使用 StringBuilder 代替 string 此时能提升不少的性能
条件分支的合并
对于同一对象非白即黑的判断,用if……else if……,而不是if……if……两次判断
如以下代码
if (n > 10)
{
// 业务
}
if (n < 10)
{
// 业务
}
明显此时的 n 如果大于 10 那么进入上面分支,此时就不可能进入下面分支。因此使用 else if 可以减少一次判断逻辑
if (n > 10)
{
// 业务
}
else if (n < 10)
{
// 业务
}
文件路径相关
获取文件夹
如果看到获取文件夹的代码是通过自行寻找 \ 字符判断的,如以下逻辑
var dir = fileName.Substring(0, fileName.LastIndexOf("\\", StringComparison.Ordinal));
可以使用 Path.GetDirectoryName 代替,如以下代码
var dir = Path.GetDirectoryName(fileName);
判断文件夹不存在,创建文件夹
默认在 Directory.CreateDirectory 方法里面已包含了判断文件夹是否存在,如果存在就不重复判断的逻辑,因此在 Directory.CreateDirectory 之前判断文件夹是否存在的代码可以删除,如以下逻辑
if (!Directory.Exists(dir))
{
Directory.CreateDirectory(dir);
}
可以删除判断文件夹是否存在的逻辑,如以下代码
Directory.CreateDirectory(dir);
拼接路径
如果看到有代码自己使用 / 或 \ 拼接路径,可以使用 Path.Combine 或 Path.Join 方法代替。对于新代码来说,推荐 Path.Join 而不是 Path.Combine 方法
判断文件存在
如果判断的文件是属于可以被用户直接输入的,小心不要在主 UI 线程上判断,因为可能用户输入的格式不对,导致当成网络资源,会让判断文件存在这个同步方法等待超长
详细请看 dotnet 警惕判断文件是否存在因为检查网络资源造成超长等待
异步多线程
Task
如果一个 Task 在做耗时任务,需要看这个任务是不是会使用很长的时间,如果会就需要设置为长时间线程
设置异步方法返回值为 void 不等待
如果设置了异步方法,而且设置了方法的返回值为 void ,那么需要确认是否会出现重入的情况。也就是这个函数可能被多次调用,而且因为没有等待,相同的逻辑被进入多次
小心 async void 后台线程异常
在 dotnet 的设计里面,如果存在一个后台线程未捕获异常,那整个进程将会挂掉。什么是 后台线程未捕获异常?这里需要区别于 Task 返回值的异常,对于异步来说,使用 async void 的方法就是线程的顶端,这个方法里面如果再对外抛出任何的异常,将属于后台线程未捕获异常,将会挂掉整个进程。简单说就是 async void 里,存在任何没有接住的异常,都会挂掉进程
而 async void 的包含了两个实现,一个就是方法,一个就是 Lambda 表达式
如下面的 Foo 方法,就属于 async void 方法,一旦对外抛出异常,那差不多这个进程就凉凉了。且这可没有统一的救的方法哦
private async void Foo()
{
// 可能抛出异常的代码(无论这个抛出是否是调用的其他的方法等,都算)
}
如下面的事件加等的 Lambda 表达式,也是一样
F1.FxEvent += async () => { throw xxx; }
代码审查看到所有的 async void 和 += async 的代码时,需要看看里面的逻辑是否足够简单,或者是已经捕获了足够的异常,防止进程直接挂掉且没有日志等。当然,例外项是在执行线程是存在线程同步上下文情况时,可以忽略此问题。比如在 WPF 的 UI 线程里面,那此时 async void 则是安全的,因为所有抛出的异常还可以进入到 Dispatcher 的 UnhandledException 里,可以执行更多的处理
详细请看 dotnet 警惕 async void 线程顶层异常
异步 async void 无效等待
如看到以下代码格式,在一个 async void 方法里面执行 await 等待一个 Task 逻辑。其实这里等待和不等待都是相同的业务逻辑。在使用 ConfigureAwait 为 false 时,就一定不会切换到 WPF 等的主线程上,丢失统一收集
async void Foo()
{
await FooAsync().ConfigureAwait(false);
}
上面代码里面如果 FooAsync 炸掉,那将会进入 AppDomain.CurrentDomain.UnhandledException 里面,且 IsTerminating 是 true 的值,表示将炸掉应用
改进的方式是不做等待,如以下代码
void Foo()
{
_ = FooAsync();
}
在似乎所有情况下,两个代码的在业务上是等价的,可以放心更改。如此抛出异常只会进入 TaskScheduler.UnobservedTaskException 里面,这里的异常在从 .NET Framework 4.5 开始,这里异常不会导致进程意外终止
锁的对象应该是不变的对象
看到使用 lock 时,请关注 lock 的对象。按照 lock 的工作原理,应该 lock 一个多线程访问的时候为共同的对象。根据这一点可以了解到有以下需要注意的套路
- 是否 lock 了一个局部创建的变量
- 是否 lock 了一个本业务外的对象
- 是否 lock 了一个被复制结构体
咱一条条过一下
如下面代码,咱在代码里面 lock 了一个局部创建的变量。那么此时这个变量不能代表多线程进来的时候能访问的相同的对象, 因此这段逻辑的 lock 和没有使用 lock 是等价的
public void Foo(A a)
{
var b = new object();
lock (b)
{
// 业务
}
}
稍微改一下上面代码,咱 lock 的是传入的参数,请问此时是否是安全的
public void Foo(A a)
{
lock (a)
{
// 业务
}
}
此时代码是挖坑代码,为什么?在写的时候,也许大部分进入 Foo 的线程能拿到相同的 a 对象,此时的lock就能生效。但是如果后续小伙伴改动了上层业务逻辑,传入的 a 不是相同的对象,那么就 gg 了。相信后续也需要用比较多的精力才能调试出来这里的坑
好,下一条,是否 lock 了一个本业务外的对象
这个问题是也许会出现相互等待的锁,因为很难了解到本业务外的对象是否也会被其他业务拿来作为锁的对象。此时就可能出现了某个线程获取了 A 对象的锁,然后等待本线程执行完成。但是本线程又想要获取 A 对象的锁,此时就挖了一个大坑
不经意会写出的坑还有如下代码
lock ("林德熙是逗比")
所有字符串常量只要字面值相同,就是相同对象。敲黑板,这一点很重要,尽量不要将字符串作为锁对象
最后一条,根据 lock 的定义,和第一条相同的坑,因为结构体每次获取都是复制新的值,此时是不安全的,也就是两次结构体虽然代码看起来是相同的对象,但是实际上存在了结构体的复制。虽然一般小伙伴写不出这样的代码,但是写出来就是挖坑
代码审查到锁要求第一个注意的是是否使用了相同的对象,以及使用用的对象是共享的,会被其他业务拿来作为锁的对象
时间
延迟的目的要说明清楚
如图
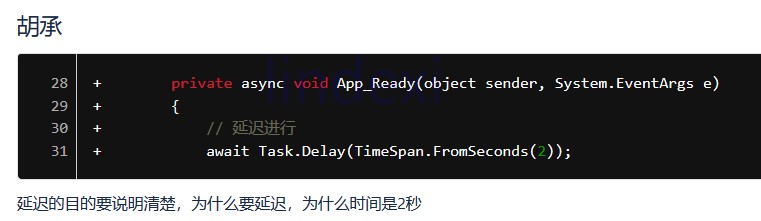
看到 await Task.Delay(TimeSpan.FromSeconds(2)); 的代码需要留意一下,也许这是逗比代码
DateTime 和 DateTimeOffset
对于需要存储下来的时间,或者是需要跨设备通讯的时间对象来说,推荐使用 DateTimeOffset 而不是 DateTime 类型。原因是 DateTimeOffset 类型是带时区的,而 DateTime 是不带时区的
在当前这个世界,如果告诉是早上 9 点,请问对应到北京时间是几点?只使用 DateTime 类型是如果知道的,因为 DateTime 没有存储时区的概念。在使用 DateTimeOffset 时,可以明确告诉是北京时间早上 9 点。于是在进行跨设备通讯时,多个设备的系统使用不同时区,也不会出现问题
只有在本地储存时,或者是瞬时使用的,才可以使用 DateTime 类型,其他情况大部分都属于不安全的。如果啥都不想去思考,那就使用 DateTimeOffset 好了
判断时间距离
在需要判断距离当前时间是否超过几天或几个小时等,将会使用类似 DateTime.Now - _lastXxTime > XxTimeSpan 的代码,着重代码审查在于看是谁减去谁,以及判断的大于小于符号是否写反。可以尝试想一下业务逻辑与时间判断,看看是不是写反了
另外,在有些业务是需要更新最后的时间,需要在代码审查看一下,是否忘记更新最后时间了
Obsolete 标记建议告知新的方法
咱可以给不适用的属性或方法或类表示 Obsolete 特性,这就能告诉开发者不建议使用此方法或属性等。此时既然建议了不要使用,那么有啥可以代替,或者应该如何做?此时推荐写在 Obsolete 里面,告诉开发者推荐的做法
因此如果代码审查看到仅有 [Obsolete] 就需要提示添加告诉开发者推荐的做法
在 Obsolete 上添加 EditorBrowsable 特性让 IDE 不加上提示
如果某个成员被标记了 Obsolete 了,那么理论上是不建议后续的开发者还见到的,此时可以考虑加上 EditorBrowsable 特性,让 IDE 不会在代码智能提示的时候列出这一项,写法大概如下
using System.ComponentModel;
using System;
[EditorBrowsable(EditorBrowsableState.Never)]
[Obsolete("这是一个不对的实现,请使用 Foo 代替")]
是否吃掉异常
如果运行某个业务,然后这个业务没有按照预期执行,也没有什么日志输出。那么此时的调试就坑了。也就是说业务吃掉了异常,会让调用业务的上层觉得很诡异,因为异常没有抛出,上层业务不知道存在异常。如果此时也没有做日志,那么小伙伴想想可以如何调试
try
{
// 业务
}
catch
{
}
在代码审查看到吃掉全部异常的,就需要问问小伙伴是否必要,另外需要问问他是否可以记一下日志
多框架差异相关
尽管 dotnet 系的 API 兼容性做的非常好,但是这么大的一个框架,每个版本之间,或多或少都有一些变更。而有一些变更是破坏性的行为,这些就需要在代码审查的时候关注。如果审查的代码是一个基础库,基础库包含了对多个框架版本的支持,例如在 TargetFrameworks 里面写的是 net45 和 net6.0 那就需要关注一下,有没有 API 刚好是在 net45 和 net6.0 的行为出现变更的
其实如果是 API 不兼容,那问题不大,构建不通过就可以提醒开发者。但如果是行为变更,也就是 API 是兼容的,但是相同的调用方法,行为却不同,那就也许有坑了。因为开发者本身也没有去测试多个框架版本新的行为
好在软的文档写的好,每个版本更改了哪些破坏改动,都会记录。详细请看 官方文档
启动进程 Process 的行为变更
这个行为变更对 Windows 应用的影响是最大的,其原因在于在 .NET Framework 全系列版本下,都是在 Start 的时候,默认采用 Shell 的方式其他。而在 .NET Core 和 .NET 5 和以上版本,采用的都是默认 UseShellExecute 为 false 的方式
这两个的差别在于启动进程的行为不同,例如通过 Shell 启动的方式,可以实现默认打开文件,跳转链接等等行为。细节请参阅 C#/.NET 中启动进程时所使用的 UseShellExecute 设置为 true 和 false 分别代表什么意思?
建议的方法是在启动进程的时候,显式设置 UseShellExecute 属性,如此即可解决 .NET Framework 和 .NET Core 默认参数的不同,从而让软件运行不符合预期
var processStartInfo = new ProcessStartInfo(exe, "参数")
{
UseShellExecute = true, // 根据需求设置为 false 的值或者 true 的值,但是一定要写
};
var process = Process.Start(processStartInfo);
process.WaitForExit();
如此软件的调用 Process 启动的行为就是可预期的
如果没有设置,也许就会在 .NET Framework 运行好好的,然而在 .NET Core 行为不符合预期,或者反过来。例如 dotnet 启动进程传入不存在的文件夹作为工作目录行为变更
WPF 相关
以下是 WPF 专门用的代码审查,里面包括了一些性能提升的建议,以及减少踩坑的建议
空白的容器定义
如果看到了有定义 Panel 的基类如 Grid 或 Canvas 等,同时没有加上 x:Name 标识,而是这个容器里面没有任何的元素,也许这就是开发调试的时候写出的代码。一个空白的容器在运行的时候也是需要经过布局的,能省就省,如果是完全没有业务用到的,推荐删掉
背景或边框使用 Border 代替 Grid 控件
如果只是需要显示背景色或者只是为了显示边框,此时选用 Grid 控件就太重了,可以使用 Border 代替,减少内存占用以及提升对象初始化性能
公开在 XAML 中使用对象的访问权限
在 XAML 中使用的对象,包括转换器以及自定义元素等,推荐将这部分类的定义的可访问权限,在不影响整个框架设计的情况下,设置为 public 权限,用来提升 XAML 创建对象的性能
原因是在 XAML 创建对象的时候,会通过反射的方法创建,而如果是反射创建的话,使用 public 权限,可以让类的构造函数被 WPF 框架进行缓存,可以大大提高对象创建的性能
详细请看 dotnet 读 WPF 源代码笔记 XAML 创建对象的方法
尽可能使用 TextBlock 代替 Label 控件
在 WPF 中,存在一个框架设计问题是引入了 Label 这个定位不够明确的控件。在所有使用 Label 的地方,都应该尽可能使用 TextBlock 代替,用来提升性能。其实在 WPF 中 Label 也仅仅只是对 TextBlock 的封装,除了性能比 TextBlock 更差之外,几乎没有别的差别
颜色的创建
如果发现有笔刷颜色的创建是采用创建 SolidColorBrush 对象传入一个已知颜色,如下面代码
var lindexi = new SolidColorBrush(Colors.Black);
那么应该提出使用 Brushes 静态类代替
var lindexi = Brushes.Black;
如果 Color 颜色属于已知颜色,但是使用 ARGB 的方式创建,如下面代码
Color color = Color.FromRgb(0xFF, 0x00, 0x00);
那么应该建议使用 Colors.Red 代替
如果是创建了笔刷,那么尽量调用 Freeze 方法,调用之后能提升很小的性能而且可以在其他线程使用
共用的相同的资源推荐抽出来
推荐在 App.xaml 添加引用统一的颜色管理,按照视觉设计的推荐,一个应用里面不建议有大量的不同的颜色,因此完全可以做到统一的一次管理。不仅可以规范视觉设计,还可以减少画刷的重复创建提升性能
如果发现在 ListView 里面的每个项都使用一个独立的用户控件,同时用户控件里面包含了很多可以共用的资源,那么推荐抽离到 App.xaml 里面,减少资源的重复多次创建
另外,可以考虑使用 StaticResource 的方式给资源添加别名,详细请看 XAML 给资源起个好名字 用 StaticResource 起一个别名
空用户控件的 XAML 删除
如果一个用户控件的 XAML 没有代码,而且可以预期后面也不会添加 XAML 代码的,可以删除掉 XAML 文件,仅保存 cs 文件。可以提升一些性能,减少 XAML 反序列化的资源
关注 XAML 层级
在 XAML 创建的控件,默认都是按照从远离屏幕到靠近用户的顺序存放,因此新加入的更改,需要关注是否放在正确的层级里面,是否有挡住原有的控件
给 XAML 使用的类应该公开
给 XAML 里面创建的类型应该是公开的,这样才能发挥 XAML 的创建对象性能。如果类型是 internal 的,那么 XAML 每次创建都需要反射创建
在 XAML 里面的创建的类型包括了用户自定义控件和转换器等类型,这些类型推荐是作为公开的,除非是确实不能公开的类型
为什么使用公开的类型能发挥 XAML 创建对象的性能?请看 dotnet 读 WPF 源代码笔记 XAML 创建对象的方法
获得依赖属性值更新记得释放
在 WPF 中,可以获得任意 WPF 依赖对象的某个依赖属性的变更通知,如下面方式。下面代码中是获取 Border 类型的 Board 对象的 Padding 属性更改通知
DependencyPropertyDescriptor.FromProperty(Border.PaddingProperty, typeof(Border)).AddValueChanged(Board,
(s, e) =>
{
Padding = Board.Padding;
BoardPadding = Board.Padding;
});
在调用 AddValueChanged 将会添加一个静态的引用,需要在不需要使用时添加 RemoveValueChanged 进行清除。因此在代码审查,发现了使用委托的形式加上了 AddValueChanged 方法就可以证明没有调用 RemoveValueChanged 方法,也就是说将会让传入的各个参数的对象都不会被回收
推荐的方法是添加一个方法代替委托,然后在不使用的时候调用 RemoveValueChanged 方法
DependencyPropertyDescriptor.FromProperty(Border.PaddingProperty, typeof(Border)).AddValueChanged(Board, Board_OnPaddingChanged);
// 在不使用的时候调用 RemoveValueChanged 方法
DependencyPropertyDescriptor.FromProperty(Border.PaddingProperty, typeof(Border)).RemoveValueChanged(Board, Board_OnPaddingChanged);
详细请看 WPF 开发
继承路由事件参数记得重写 InvokeEventHandler 方法
如果自己写了某个类型作为路由事件参数,如下面代码
public class LindexiRoutedEventArgs : RoutedEventArgs
那么推荐重写 InvokeEventHandler 方法,重写了这个方法,可以将传入的 Delegate 强转为自己已知的委托类型,然后触发。这样的性能会比较好
以下是一个推荐的路由事件定义的方法
public class Owner : UIElement
{
public static readonly RoutedEvent LindexiEvent = EventManager.RegisterRoutedEvent("Lindexi",
RoutingStrategy.Bubble, typeof(LindexiRoutedEventEventHandler), typeof(Owner));
public event LindexiRoutedEventEventHandler Lindexi
{
add { AddHandler(LindexiEvent, value); }
remove { RemoveHandler(LindexiEvent, value); }
}
public void RaiseLindexiEvent()
{
RaiseEvent(new LindexiRoutedEventArgs(LindexiEvent, this));
}
}
public class LindexiRoutedEventArgs : RoutedEventArgs
{
/// <inheritdoc />
public LindexiRoutedEventArgs()
{
}
/// <inheritdoc />
public LindexiRoutedEventArgs(RoutedEvent routedEvent) : base(routedEvent)
{
}
/// <inheritdoc />
public LindexiRoutedEventArgs(RoutedEvent routedEvent, object source) : base(routedEvent, source)
{
}
protected override void InvokeEventHandler(Delegate genericHandler, object genericTarget)
{
// 这个方法的重写是可选的,用途是为了提升性能
// 如无重写,底层将会调用 Delegate.DynamicInvoke 方法触发事件,这是通过反射的方法调用的
var handler = (LindexiRoutedEventEventHandler) genericHandler;
handler(genericTarget, this);
}
}
public delegate void LindexiRoutedEventEventHandler(object sender,
LindexiRoutedEventArgs e);
不要在 OnRender 里面抛出事件
在 OnRender 方法里面最好只做和渲染相关的逻辑,禁止任何业务逻辑。不要在 OnRender 里面抛出事件,因为不知道此事件将会执行什么,是否会抛出异常
不需要命中测试的自定义控件关闭命中测试
如果自定义的控件不需要有命中测试的功能,如只是用来做界面渲染的,没有任何交互,考虑关闭此控件的命中测试,如在静态构造函数加上如下代码
IsHitTestVisibleProperty.OverrideMetadata(typeof(你的自定义控件), new UIPropertyMetadata(false));
但是以上代码也会挖坑,如果后续需要有交互了,说不定找不到这个代码,从而不知道为什么自己写的控件没有交互
窗口相关
调用 Close 关闭模态窗口
在 WPF 里面,可以通过设置 Dialog 或 ShowDialog 的方式给某个现有的窗口设置一个模态子窗口。在调用 Close 关闭模态子窗口时,可能会触发一个 Windows 的(非 WPF 的)一个坑,那就是在关闭模态窗口后,父窗口居然失去焦点跑到了其他窗口的后面的问题
复现步骤是:
- 弹出一个模态窗口,然后将模态窗口的父窗口设置为自身窗口;
- 切换到其他程序窗口中(比如 Windows 资源管理器窗口);
- 切换回此模态窗口,然后关闭这个模态窗口上
现象是模态窗口关闭后,父窗口并没有回到当前的顶层显示中。取而代之的,是其他程序的窗口,比如 Windows 资源管理器窗口
规避方法是重新激活所有者窗口,如以下代码
public ChildModalWindow()
{
Closing += (sender, e) => Owner?.Activate();
}
在代码审查看到 Close 关闭窗口,需要先看看是否关闭的是一个模态窗口,如果是模态窗口,看一下上面的 Closing 代码是否有编写,如没有编写,需要评估一下 父窗口居然失去焦点跑到了其他窗口的后面的问题 是否在需求上需要考虑。如需要考虑,那就推荐开发者加上以上的补丁代码
此问题详细请看 解决关闭模态窗口后,父窗口居然失去焦点跑到了其他窗口的后面的问题 - walterlv
线程
不要开后台线程只用来调 Dispatcher 回 UI 上
看看下面的逗比代码,大概就是 10 行代码 10 个吐槽点
ThreadPool.QueueUserWorkItem(o =>
{
Application.Current.Dispatcher.BeginInvoke(
DispatcherPriority.SystemIdle,
new Action(async () =>
{
Thread.Sleep(100);
UserControl1.Foo();
}));
});
吐槽点:
-
开一个线程池任务,只是为了回到 UI 调用 UserControl1.Foo 而已。浪费线程池资源,直接调用即可 Dispatcher 调度即可
-
使用 ThreadPool.QueueUserWorkItem 而不是 Task.Run 调度线程池任务。以上的代码如此简单,直接 Task.Run 即可
-
使用 Dispatcher.BeginInvoke 而不是 Dispatcher.InvokeAsync 方法。 不想思考的话,默认使用 Dispatcher.InvokeAsync 就好了,除非有特别需求,否则少用 Dispatcher.Invoke 方法或 Dispatcher.BeginInvoke 方法
-
使用 SystemIdle 优先级可能过低,需要看一下是否真需要如此低优先级。此优先级可能会很长时间都不执行
-
使用
new Action的显式写法,而不是直接委托推导。属于多余的代码,但也可能是受限 Dispatcher.BeginInvoke 方法 -
在 Action 里面使用 async 异步。这就等于是 async void 线程顶层,异步是否完全执行完成,是无法被上层感知到的。再加上 async void 属于 线程顶层,导致一旦存在任何异常,将可能让进程退出
-
写了 async 但是函数体不存在任何 await 代码,白跑了异步
-
调度回 UI 只是为了 Thread.Sleep 去卡 UI 线程,图什么呢。简单优化是 Thread.Sleep 尽可能改 Task.Delay 方法。针对以上代码,更具体的更改是在进入 UI 之前,自己 Task.Delay 一下
以上是比较直接的吐槽点,来试试大家还能不能找出更多的吐槽点
根据以上的吐槽点,改造之后的代码:
// 刚好调用就在 UI 上的,且不明确需要优先级的:
await Task.Delay(TimeSpan.FromMilliseconds(100));
UserControl1.Foo();
// 调用是在后台线程上的,或明确需要优先级的:
await Task.Delay(TimeSpan.FromMilliseconds(100));
_ = Application.Current.Dispatcher.InvokeAsync(() => UserControl1.Foo(), DispatcherPriority.SystemIdle);
调用 Dispatcher.Invoke 时需要判断是否可以使用 Dispatcher.InvokeAsync 代替
在使用 WPF 的 Dispatcher.Invoke 时,如果遇到异步,是有可能出现锁的相互等待。因此更多推荐使用 Dispatcher.InvokeAsync 代替,如果可以修改为 Dispatcher.InvokeAsync 那么推荐使用 Dispatcher.InvokeAsync 代替。如果需要等待 Invoke 内容执行完成,记得使用 Dispatcher.InvokeAsync 时需要加上 await 等待
关于 Dispatcher.Invoke 锁相互等待问题,请看wpf 使用 Dispatcher.Invoke 冻结窗口
不想思考的话,默认使用 Dispatcher.InvokeAsync 就好了,除非有特别需求,否则少用 Dispatcher.Invoke 方法或 Dispatcher.BeginInvoke 方法。详细请看 WPF 使用 Dispatcher 的 InvokeAsync 和 BeginInvoke 的异常处理差别
调用 Dispatcher.Invoke 里面使用 Shutdown 方法可以使用 InvokeShutdown 代替
如下面代码
Application.Current.Dispatcher.Invoke(() =>
{
Application.Current.Shutdown(0);
});
可以使用 InvokeShutdown 代替
Application.Current.Dispatcher.InvokeShutdown();
但无论如何这都是不推荐的,正确的方法应该是使用 Application.Current.Dispatcher.InvokeShutdown 或者是 Application.Current.Shutdown 进行退出,详细请看下文
不要使用 Dispatcher.InvokeShutdown 方法退出应用
应该使用 Application.Current.Dispatcher.InvokeShutdown 或者是 Application.Current.Shutdown 进行退出,不应该使用 Dispatcher.InvokeShutdown 方法退出应用
详细请看 WPF 警惕使用 Dispatcher.InvokeShutdown 方法退出应用 将不触发 Application.Exit 事件
给 DispatcherTimer 设置 Interval 属性
如果创建一个空的 DispatcherTimer 对象,没有设置 Interval 属性,也没有加上事件,直接开始,那将会空跑 UI 线程,让 UI 线程开始拉满一个 CPU 资源
这是因为 DispatcherTimer 对象在没有设置 Interval 属性时,此属性的值就是 0 时间,也就是不断执行
代码审查的时候,看到 DispatcherTimer 需要看看 Interval 属性是否被设置了,和设置的时间是多少
更多请看 WPF 如何知道当前有多少个 DispatcherTimer 在运行
最后再附加小笑话
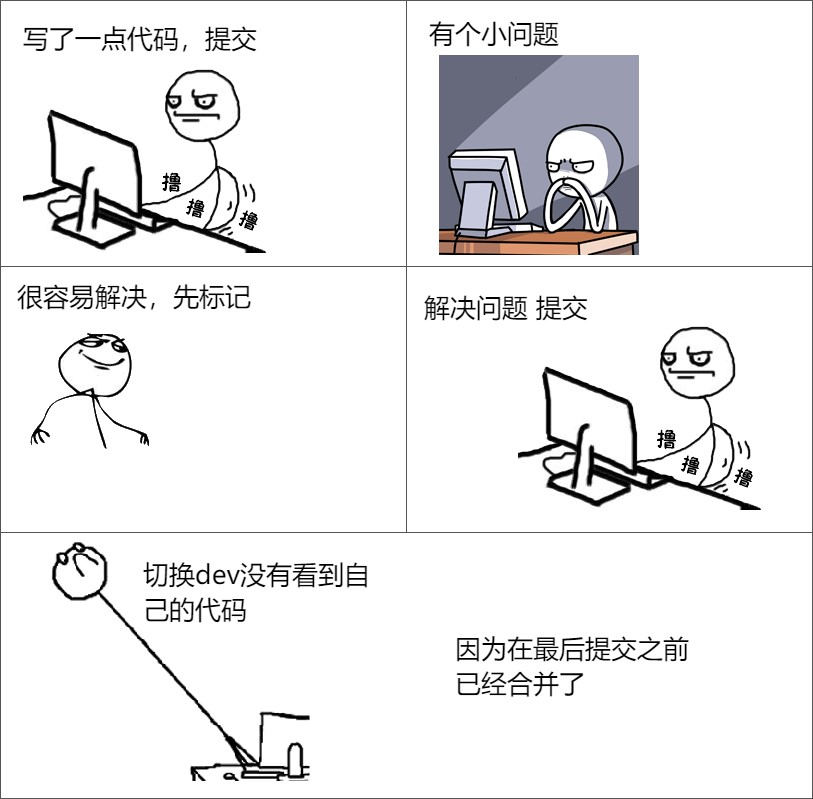
谁删了我的代码
德熙看到了胡承评论了代码的变量名不好理解,因为德熙觉得这个变量名修改是很快的事情,于是就点了已解决。这时德熙在本地修改了变量名,出去和小伙伴聊天,回来就上传代码。过了几分钟,发现dev上没有自己的代码,而且MegerRequest合并了。是谁删了我的代码?
实际上在德熙提交之前,胡承已经把代码合并到dev了,如果一个分支在合并到dev之后的提交是不会自动合并到dev,需要再次提交请求才会合并。
如果要避免再次发生这个事情,那么在解决完之后提交再点击以解决
本文会经常更新,请阅读原文: https://blog.lindexi.com/post/dotnet-%E4%B8%80%E4%BA%9B%E4%BB%A3%E7%A0%81%E5%AE%A1%E6%9F%A5%E5%A5%97%E8%B7%AF.html ,以避免陈旧错误知识的误导,同时有更好的阅读体验。
如果你想持续阅读我的最新博客,请点击 RSS 订阅,推荐使用RSS Stalker订阅博客,或者收藏我的博客导航
 本作品采用
知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议
进行许可。欢迎转载、使用、重新发布,但务必保留文章署名林德熙(包含链接:
https://blog.lindexi.com
),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。如有任何疑问,请
与我联系
。
本作品采用
知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议
进行许可。欢迎转载、使用、重新发布,但务必保留文章署名林德熙(包含链接:
https://blog.lindexi.com
),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。如有任何疑问,请
与我联系
。

无盈利,不卖课,做纯粹的技术博客
以下是广告时间
推荐关注 Edi.Wang 的公众号

欢迎进入 Eleven 老师组建的 .NET 社区

以上广告全是友情推广,无盈利
